Identifying Reference Districts by means of Machine Learning and Open-Source Data
Keywords: District planning, scaling, open-data, machine learning, clustering
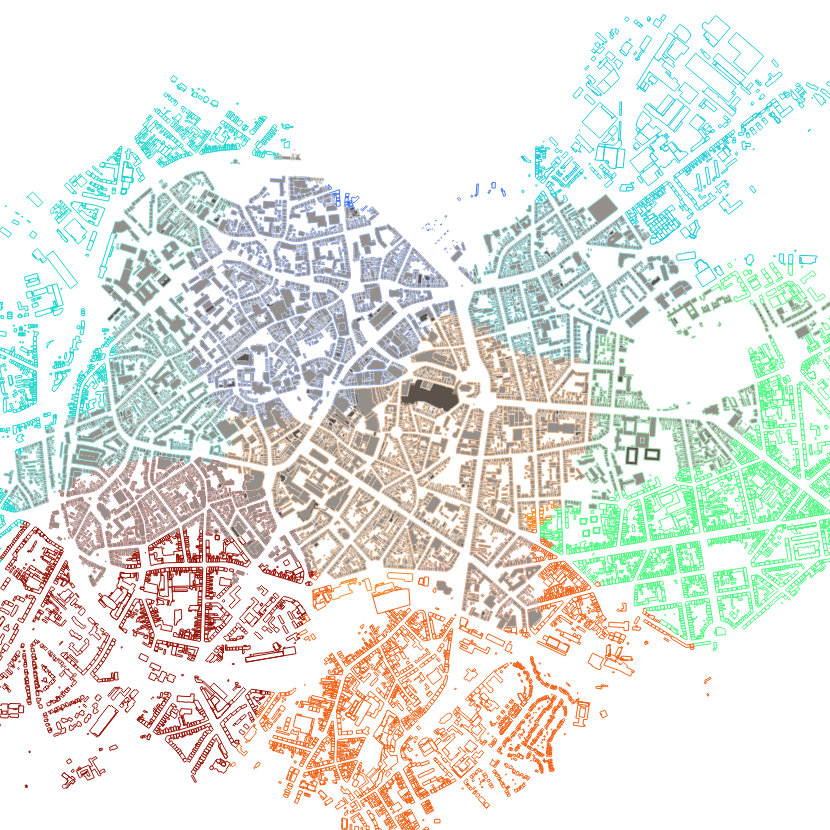
It explores identifying reference districts through Geographic Information System (GIS)-based machine learning and public data, utilizing clustering methods to analyze spatial and socio-infrastructural metrics. The methodology yields significant insights into district definition and characterization, integrating technical and human understanding of urban dynamics. The findings highlight the importance of attribute selection in neighborhood classification and extend beyond mathematical validation to include social context comprehension. The developed technique is applied to a case study involving the city of Aachen.